One of the biggest challenges when collaborating with others in developing software and websites is setting up the development environment. The good ol “it works on my machine…” problem.
Well, this is no panacea for development, but it does a good job of setting up a basic environment pretty quickly.
You’re in for a special treat, because I’m going to show you not one (1), but two (2) different development environments; one for PHP, MySQL, Apache and phpMyAdmin, and one for Python (Flask) and PostgreSQL with pgAdmin. Each of these in a Docker container for ease of use.
Pre-requisites
For any of this to work, make sure you have Docker Desktop installed and running.
We’ll be using a terminal application for running some commands, so you’ll need some familiarity with that too.
Git is used to copy the files from the GitHub repo, but you can also download them as a zip file.

PMAMP
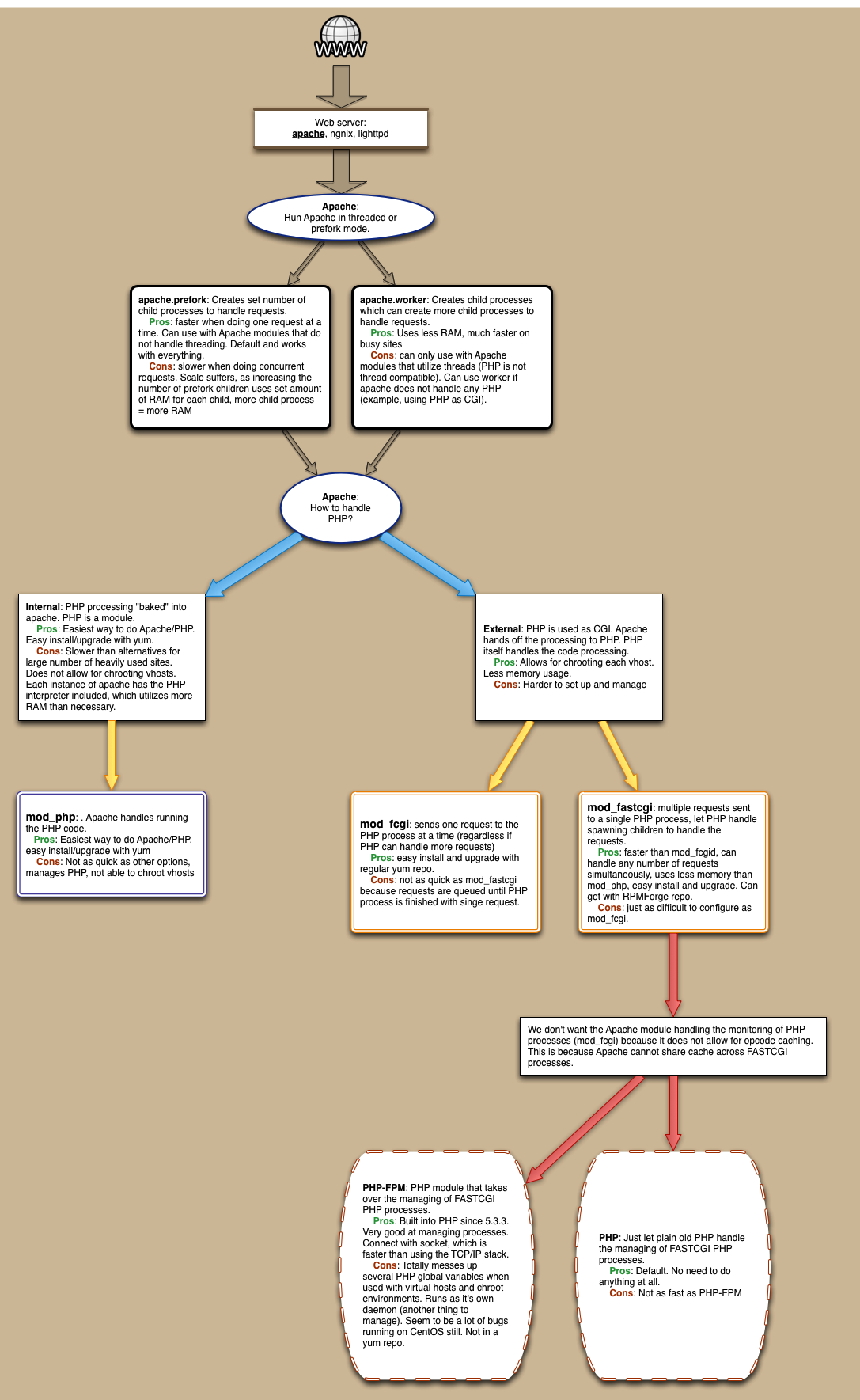
We’ll tackle the PhpMyadmin Apache Mysql Php (PMAMP) environment first.
After setting this up, we’ll have a place to put PHP code, a running Apache web server, a MySQL server and a running instance of phpMyAdmin.
The quickest way to get this going is to download the files from this GitHub repo https://github.com/ammonshepherd/pmamp
git clone https://github.com/ammonshepherd/pmamp.git
Change into that directory.
cd pmamp
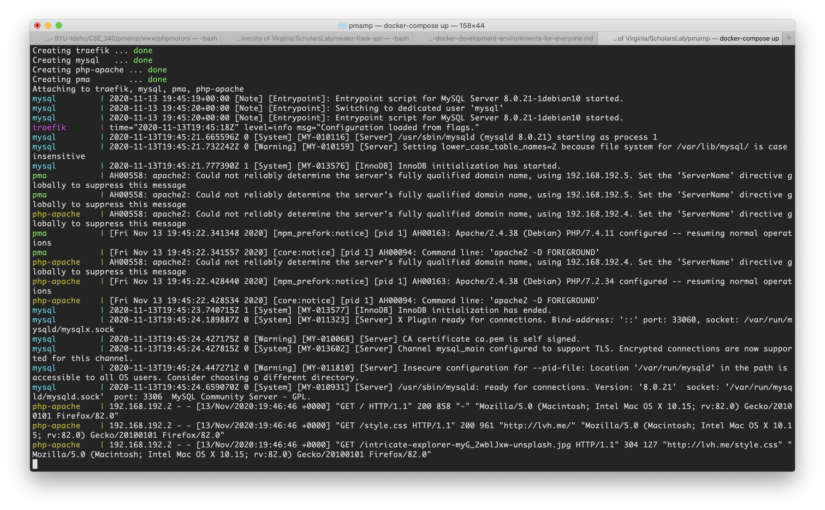
And start the Docker containers
docker-compose up -d
You can view the website at http://lvh.me. lvh.me is just a nice service that points back to your local machine (127.0.0.1 or localhost). It makes it look like you are using a real domain name.
You can view phpMyAdmin at http://pma.lvh.me.
You can even use a real domain name. Just edit the docker-compose.yml file. There is a line like this:
- "traefik.http.routers.php-apache.rule=Host('lvh.me', 'pmamp.lvh.me', 'example.com')"
Just add your domain to the list (or remove the other ones). Each entry must use the backtick, rather than the single quotes. WordPress mangles the backticks, so I am using single quotes here.
Now you just need to let your computer know to redirect all traffic to that domain name to itself.
You’ll need to edit the /etc/hosts file (Linux or Mac), or c:\windows\system32\drivers\etc\hosts (Windows). Now you can develop for any domain name right on your computer as if it were using the actual domain name.
Put all of your website files in the ‘www’ folder and you’re ready to develop!
Check the README at https://github.com/ammonshepherd/pmamp for more details on how it works and things to change.
To stop the services (turn off Apache, MySQL and phpAdmin) run
docker-compose down
in the same directory where the docker-compose.yml file lives.

pFp
The set up for Python (using a Flask app) and PostgreSQL is exactly the same process.
Grab the files from https://github.com/ammonshepherd/pfp.
git clone https://github.com/ammonshepherd/pfp.git
cd pfp
docker-compose up -d
You now have a running Flask app at http://lvh.me, or http://pfp.lvh.me and a running pgAdmin application at http://pga.lvh.me.
The same trick for custom domain names applies here too.
And also check out the README for more details: https://github.com/ammonshepherd/pfp
Follow the same commands above to shutdown the Python, PostgreSQL and pgAdmin containers.